Capitolo 073 - Universal binary
Trasformo un po' d'applicazioni in Universal Binary
Sorgenti: documentazione Apple
Prima stesura: 8 luglio 2006
Binari universali
Come dovrebbe essere noto, Apple ha deciso di equpaggiare i propri computer con processore Intel piuttosto che continuare ad affidarsi all'architettura PowerPC (di Motorola/Freescale/IBM). La transizione pone qualche problema agli sviluppatori, a causa della differente architettura dei processori. Come al solito, tuttavia, Apple semplifica la transizione, sia per l'utente comune attraverso l'interprete Rosetta, sia per lo sviluppatore, fornendo gli strumenti necessari.
È invece meno noto che sono da poco possessore di un iMac intel (con XCode 2.3); è quindi giocoforza affrontare la questione della migrazione, ovvero la creazione di applicazioni Universal Binary (UB).
Parto dalla documentazione Apple, ovvero Universal Binary Programming Guidelines, second edition. Le assunzioni che il documento prevede siano soddisfatte per i programmi da rendere UB sono molto semplici: devono essere applicazioni sviluppate per Macintosh con Carbon, Cocoa o Java. Rientrano in tutto le applicazioni che mi appresto a rendere UB, ovvero, CdCat (rilascio del capitolo 63), lo screensaver (capitolo 64), cocoaurl (capitolo 65) e YahFortune (capitolo 70). Ognuna di queste applicazioni ha delle peculiarità che permettono di testare la conversione in maniera, credo, piuttosto completa.
Converto il catalogo
Comincio con CdCat. Il punto di partenza è l'applicazione originale, che mi informa essere una normale applicazione PCC.
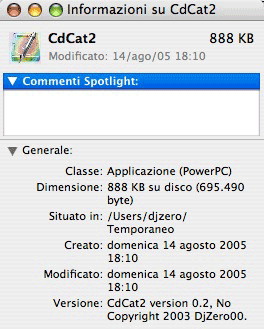
Va detto che funziona tranquillamente così com'è anche sullo iMac intel, senza colpo ferire. Tuttavia, voglio rendere il tutto UB. Importo il progetto e, dopo qualche traversia di conversione del file del progetto, ricompilo tutto senza cambiare nulla.
Ma il prodotto non è UB, è semplicemente intel.
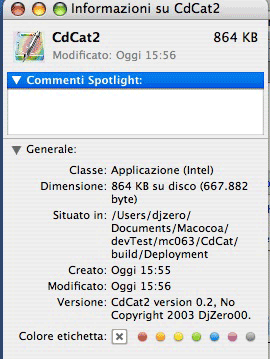
Si vede che non è così banale. Leggo il documento Apple, e scopro di dover fare qualcosa. Mi figuro che le stesse operazioni funzionino anche su macchine PowerPC, purché, ovviamente, la configurazione sistema (10.4) e Xcode (2.3) siano soddisfatte.
In primo luogo, devo essere sicuro di utilizzare la versione 4.0 del compilatore GCC. Essendo di default così in Xcode 2.3, devo far nulla. Il progetto però va configurato per lavorare in Cross-development, cioè per produrre del codice non necessariamente per la macchina sulla quale sto lavorando. Si cerca quindi il pannello delle informazioni del progetto, e nel tab General cerco la sezione apposta.
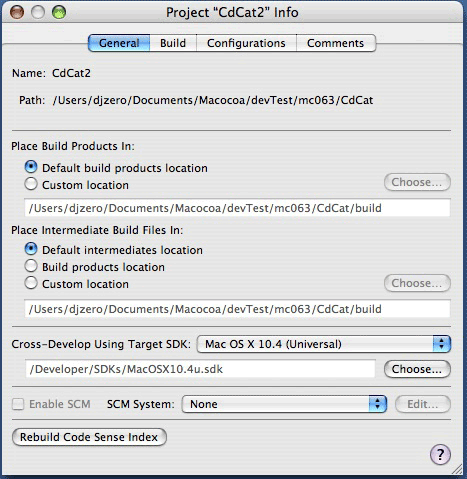
Seleziono il cross development per Mac OS X 10.4 (Universal), in modo da essere sicuro. XCode mi minaccia con un messaggio di avviso, ma la documentazione mi dice di andare avanti tranquillo.
Il passo successivo è di cambiare le impostazioni dell'architettura. Rimango nello stesso pannello ma cambio tab, e vado in Build. Qui devo effettuare i cambiamenti sia per la configurazione Development (ma anche no, dipende se voglio generare codice per PPC anche in sede di sviluppo) sia e soprattutto per la configurazione Deployment. Ricordo che la configurazione Development utilizza alcuni accorgimenti (ZeroLink, Fix and Continue, eccetera) che permettono di velocizzare le fasi di sviluppo. La configurazione Deployment invece costruisce l'applicazione per la distribuzione, elimina gli accorgimenti visti sopra e cerca di ottimizzare il codice.
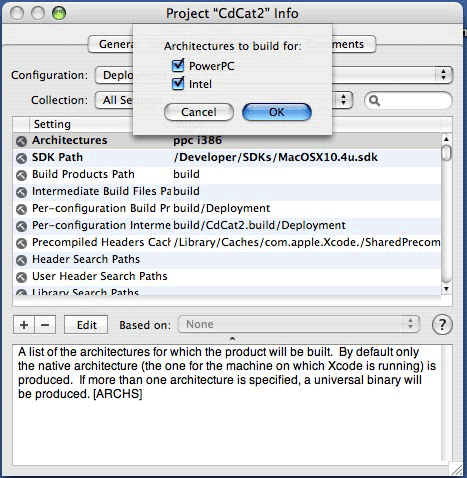
Seleziono insomma la riga Architectures e uso il tasto Edit poco sotto. Mi si apre un piccolo pannellino dove spuntare le architetture di destinazione del codice prodotto. Di default è acceso (per me che lavoro su intel) solo Intel, spunto anche PPC.
A quanto pare, ho finito. Vedo se è vero. Ricompilo tutto con la configurazione di Deployment, ed ottengo un eseguibile. Questa volta le informazioni sul file dicono che è UB.
Le dimensioni sono aumentate, come dovrebbe essere giusto (bisognerà pur conservare da qualche parte il codice da eseguire su intel e quello per PPC), ma non sono raddoppiate come ingenuamente si potrebbe pensare. Guardando all'interno dell'applicazione (da Finder, menu contestuale, Mostra Contenuto pacchetto) si nota che nessun file è duplicato, nemmeno l'eseguibile vero e proprio. Il codice per Intel dovrebbe essere lì dentro: in effetti le dimensioni di questo file sono quasi raddoppiate.
L'applicazione funziona normalmente, leggo scrivo e stampo. Fin qui, tutto bene.
La prova fondamentale tuttavia è di pigliare questa applicazione, ed i file prodotti, e sperimentare su un PPC. Sposto tutto sul mio vecchio powerbook G3 e vedo che accade. Tutto funziona. Molto bene.
E tutti gli altri
Andiamo avanti. Salvaschermo. Rifaccio le stesse operazioni (cross-development e selezione dell'architettura). Provo su intel, funziona. Provo su PPC, funziona. Bene. CocoaUrl. Funziona su entrambe le piattorme.
YahFortune. Qui ci sono diversi target. Li compilo tutti, e tutti sembrano funzionare correttamente (tuttavia, ho il sospetto, di fronte a certi comportamenti bizzarri che compaiono di tanto in tanto, ci sia qualche problema, più dell'applicazione che della trasformazione in UB...).
Insomma, la transizione in UB è parsa una passeggiata.
Punti notevoli
Ma quali sono le cose che potrebbero andare storte (e perché qui non sono andate storte)?
Essenzialmente, mi pare di capire che ci possano essere due tipi di problemi: fare di conto e l'ordine dei byte. PowerPC ed Intel sono due architetture piuttosto differenti (CISC vs RISC, per cominciare), che gestiscono le istruzioni, i dati e la memoria in maniera differente.
Le istruzioni in PPC sono sempre lunghe 4 byte, sono poche, semplici e ben ottimizzate. Le istruzioni su Intel sono di dimensioni variabile, sono tante, e qualche volta fanno lunghi giri per essere eseguite compiutamente (si fa per dire). Ciò che su PPC veniva raggiunto con eleganza ed efficienza, Intel lo fa di mera forza bruta. Lungi tuttavia dall'attribuire coloritura etica e morale sulla faccenda, passiamo ai due punti importanti.
La prima questione sono i numeri; benché rispondenti in entrambi i casi a vari standard, la trattazione differisce in qualche minuzia. Ad esempio, la divisione per zero (operazione matematicamente non lecita) produce il valore zero su PPC, senza troppi patemi. Su Intel, è una mezza tragedia, causando eccezione e blocco del programma (e qui mi pare che Intel abbia più ragione...). Pertanto, se il programma da trasformare utilizza estesamente calcoli in cui c'è il rischio di una divisione per zero, le strategie per evitarla sono teoricamente differenti nei due casi. In pratica, un buon programmatore ha già affrontato e risolto il problema evitando in generale la divisione per zero. Ugualmente, potrebbero esserci problemi quando si fanno confronti con i numeri floating point (che, a parità di valori interessati, potrebbero dare risultati diversi sulle due architetture), ma anche qui un buon programmatore ha già risolto il problema in modo indipendente dalla piattaforma. Lungi dall'essere una sagace programmatore, non ho riscontrato nei miei casi questo tipo di problemi perché i numeri hanno avuto poco impatto nelle applicazioni fin qui sviluppate.
L'ordine dei byte è invece il problema più grosso. Tutto nasce da come i dati composti da più di un byte sono conservati in memoria. Si può utilizzare la strategia big-endian, in cui i byte più significativi vengono prima di quelli meno significativi (come succede nel PPC), oppure la strategia little-endian, opposta, dove i byte meno significativi sono messi davanti (ovviamente, Intel). Non mi pare di ricordare ragioni tecniche per cui un metodo di allineamento sia migliore dell'altro, ragione per cui il mondo informatico si è diviso (a volte con toni acerrimi) tra big-endiani e little-endiani. Per inciso, il nome deriva da un episodio del libro di Jonathan Swift "I viaggi di Gulliver", in cui i lillipuzziani erano in guerra con un'altra popolazione (di pari dimensioni ma di nome differente). Le due popolazioni infatti erano in conflitto per il modo con cui utilizzavano le uova a scopi alimentari, con gli uni che le aprivano dalla parte piccola (i little-endiani), e gli altri che li aprivano dalla parte più grossa (i big-endiani). Queste profonde ed importanti differenze nella visione delle cose del mondo li ha portati ad essere nemici e combattere per lunghi anni (e quando qualcuno mi cita i viaggi di gulliver come libro per bambini, rido della sua pochezza culturale e gli faccio notare come Swift sia uno scrittore che scandagliava l'animo umano come pochi).
Tornando ai nostri byte, l'importanza dell'ordine si ha ogni volta che si organizzano in memoria strutture dati più grosse di un byte (sempre) ed ogni volta che si ha a che are con flussi lineari di dati, ovvero file su disco e connessioni di rete (che mi pare di ricordare siano quasi sempre big-endian). Per cui, ogni volta che si ci si avvicina al cuore del trasferimento di dati, occorre prestare attenzione a come si gestiscono questi byte. Confesso che all'inizio pensavo di dovermi sorbirmi tutta questa faccenda, e di dover esaminare il codice alla ricerca di sezioni dove i dati erano gestiti. Invece, dal momento che utilizzo Cocoa e non mi sono avventurato nella gestione diretta di flussi di dati, ma ho lasciato fare tutto a Objective C e le classi come NSCoding, devo fare proprio nulla e lasciare tutto intonso. Il che è un risultato non da poco.
